AWS Lambda Graviton2, cheap and slow
I was pretty pumped when I saw the announcement for AWS Lambda Graviton2 support for a couple of reasons, performance and cost. AWS have provided Graviton2 support for EC2 for a while now so it’s good to see this flow into Lambda especially if it’s going to save us a buck and it’s faster, whats not to like?
The official AWS blog has done a pretty good write up detailing how to use the new architecture type, strategies for migrating by running both your x86 and arm functions and they’ve used an open-source project to optimize the workload. Probably the most thorough write up we’ve seen for a while from AWS, which is great!
Just a side note, I’ll be talking about performance, cost and usability, there are other benefits to running Graviton2. You can read about some of the other benefits on the AWS Graviton2 page.
Video: If you want to out check devs in the shed (shout out to the local AWS Devs in the shed, Paul Kukiel and Matt Coles), this is first info I saw about Lambda Graviton2 that popped up in my feed: https://www.youtube.com/watch?v=adAvn_NxLU8
The Test Environment
I had a bit of a look around before tackling this one and found some previous writeups which used some well known tools. Shout out to Tai Nguygen Bui, I found his write up to be quite detailed and dips into API GW performance as well. In the end I selected https://artillery.io/ and a simple AWS API GW setup…and of course, everything is developed using CDK.
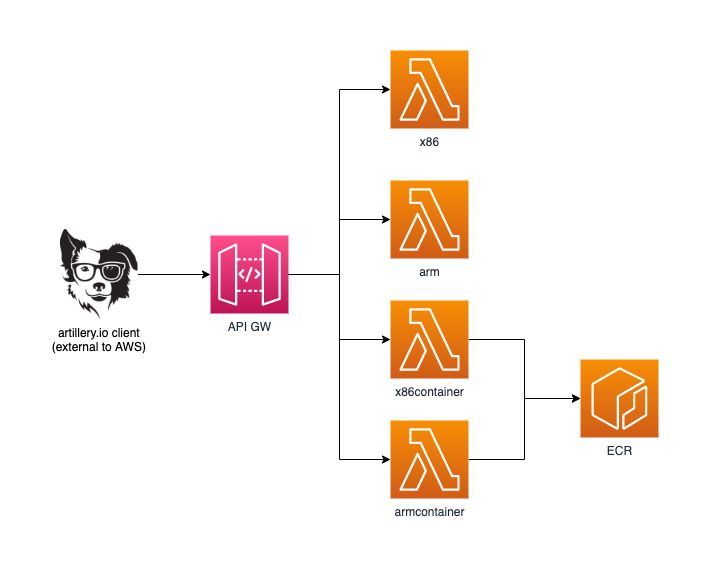
All of the testing has been completed using ap-southeast-2 (Sydney) region, any pricing is in USD from us-east-1 to make it easier.
We can see from the image above the setup is simple, we have a client using the artillery.io toolkit which is from an external network outside of AWS, this requests the API-GW using the various paths which then invoke the Lambda function and return the results.
The Lambda functions have been developed using Python and each function is the same as far as code. I added containers because I was curious about cold starts with arm and this would be the best way to find out.
Note: for the containers I updated the boto client as seen in the Dockerfile, this is the same on x86 and arm
The Code and configuration
If you’d like to play along you can replicate the environment by provisioning the stack with CDK in your account:
 GitHub
GitHubIf you want to run the artillery.io tests you’ll need to copy the perf.sample.yaml over to perf.yaml. You will also need to update the x-api-key with your API key and obviously the endpoint url as well.
You can use environment variables you prefer, see the commented out section below. Also note the region.
Sample perf.yaml
| |
What this will do is throw 27,000 requests at the API-GW which will in turn invoke each one of our lambda functions over a 15 minute window. It’s a pretty nice little tool, the end result will show if we had any errors like non HTTP 200’s.
The actual performance test itself is simple enough, the AWS blog digs into prime numbers. I wanted something different. I didn’t find anything simple enough for what I wanted, but I did see a nice little snippet that runs some simple calcuations. I’ve added some some string concatenation to it and picked an end for the loop. It’s simple enough to produce a bit of load for us to talk about.
| |
There are a few other bits and pieces that return a message in the payload but again, less important, feel free to dig into that if you like.
What did I find?
When I first developed this testing I was only looking at a simple hello world using the x86 and arm. As you can imagine the response would be so quick it wouldn’t be that interesting. I won’t be discussing anything outside of Lambda e.g. the time from the client start to finish or the API GW performance. I’m only interested in how long lambda took and what does that mean for billing.
First of the summary results from artillery
Test table summary (after cold start)
| Item | Result |
|---|---|
| Scenarios launched | 27,000 |
| Scenarios completed | 27,000 |
| Requests completed | 108,000 |
| Mean response/sec | 119.61 |
| Response time (msec) min | 158 |
| Response time (msec) max | 4551 |
| Response time (msec) median | 564 |
| Response time (msec) p95 | 631 |
| Response time (msec) p99 | 691 |
| Codes (HTTP) 200 | 108,000 |
As above, this is after the cold start. What I mean to say is I split the testing to make it easier for me to look at warm invokes only e.g. no initialization. The table above is showing that we made over 100k successful requests.
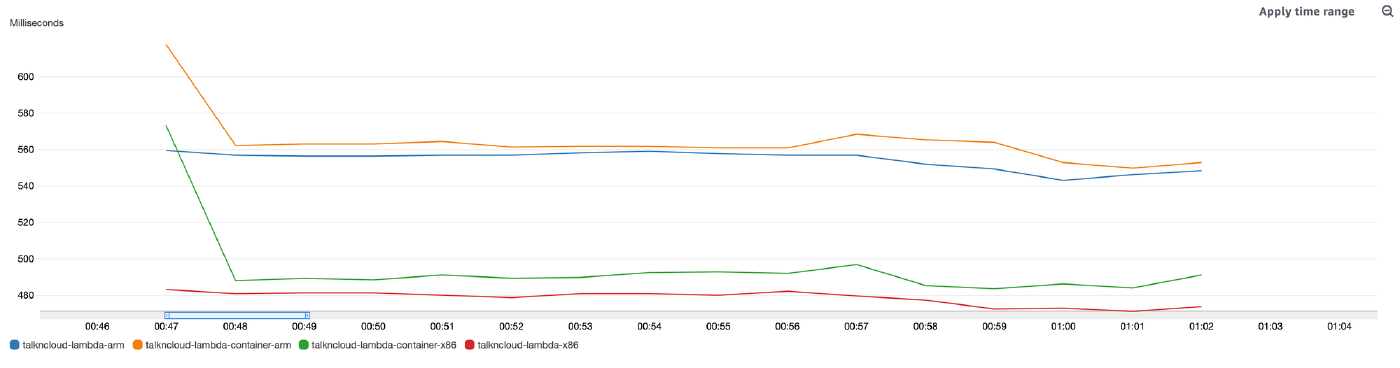
CloudWatch function comparison
The chart below is showing the function duration for all functions, this is the 15 minute of testing with 27,000 hits per function.
Note: I performed a cold start first to split the charts out, which I’ll show next.
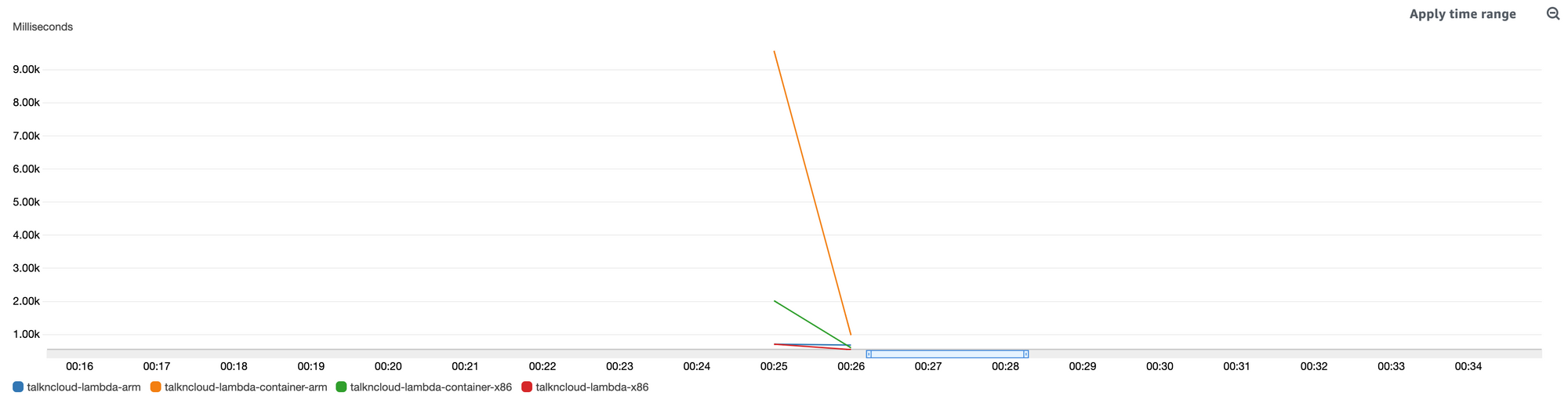
Here is the cold start, this is me basically running the test and then canceling it. The Lambda function hadn’t been invoked for days prior to these results.
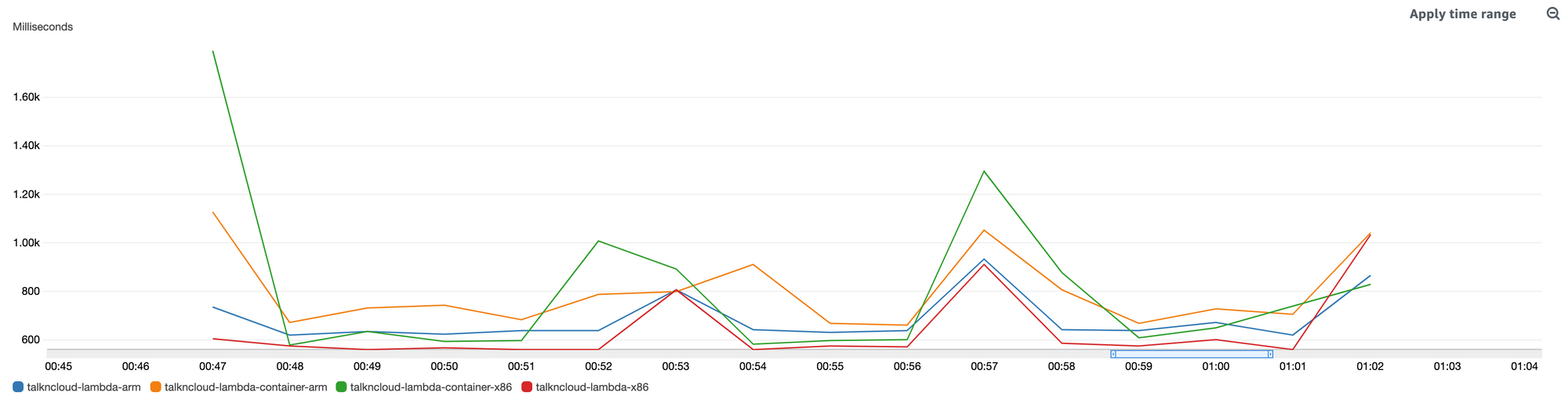
For both of these charts I’ve set the statistic to Max and Period to 1 Second. The average of the same period less the cold start shows another useful story:
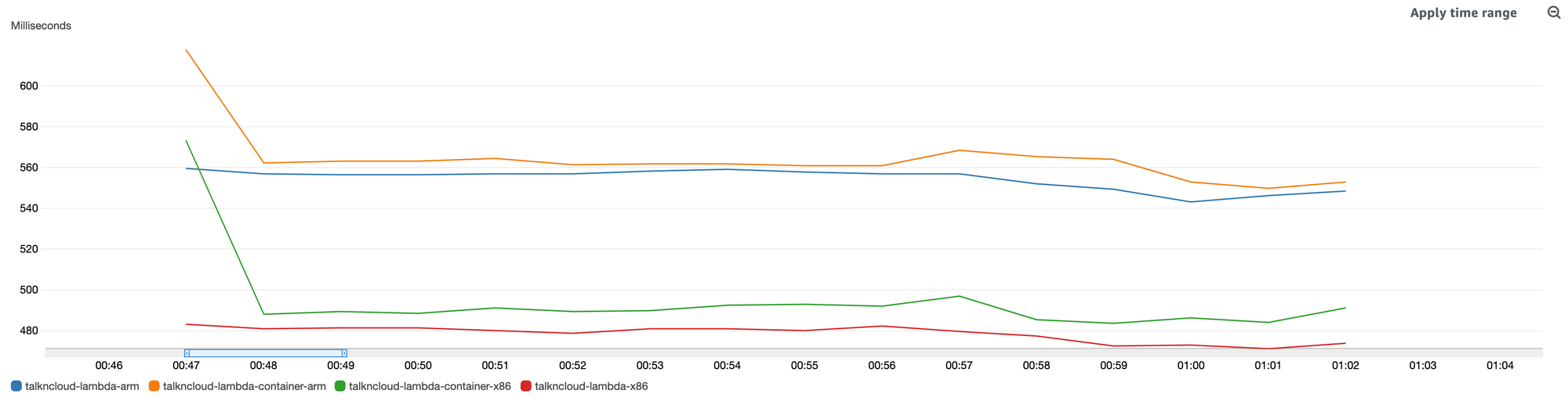
Whats interesting about these charts?
First thing, the obvious was the performance, I’m just not seeing the performance I was expecting given all the hype of Gravtion2 support for Lambda. The second was the cold start, wowzers, would you look at that arm container cold-start, it’s a good 7 seconds slower than x86.
I thought maybe the arm container was larger in size compared to x86, this might help explain something. The arm container is larger, 1MB. Not enough to explain it.
X-ray, digging a little deeper
I’m a big fan of AWS x-ray, it’s so simple to enable and provides some nice easy to use visibility of our setup. I took a closer look at the arm container startup using x-ray to confirm:

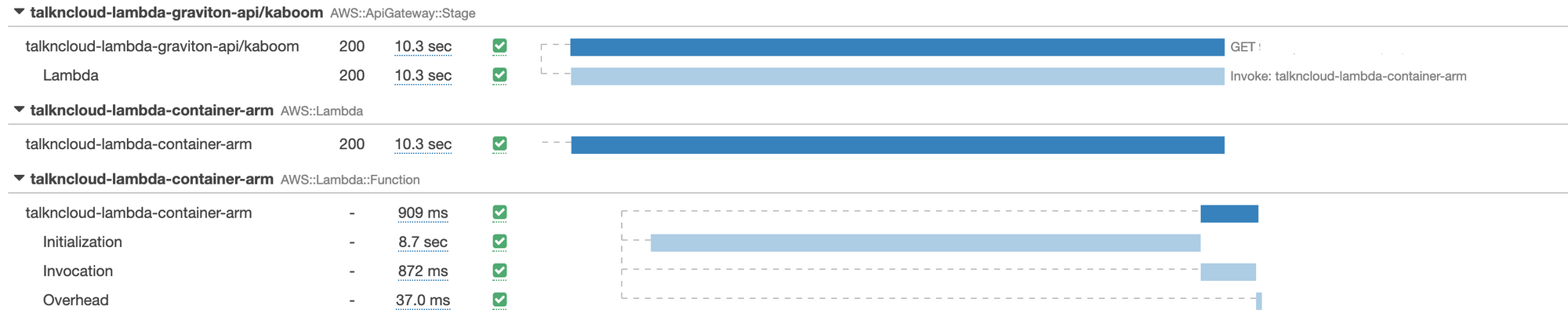
I grabbed this by sorting by response time in x-ray and selecting the highest one. We can see the initialization time of 8.7 seconds.
For comparison, here is the next highest x86 container:

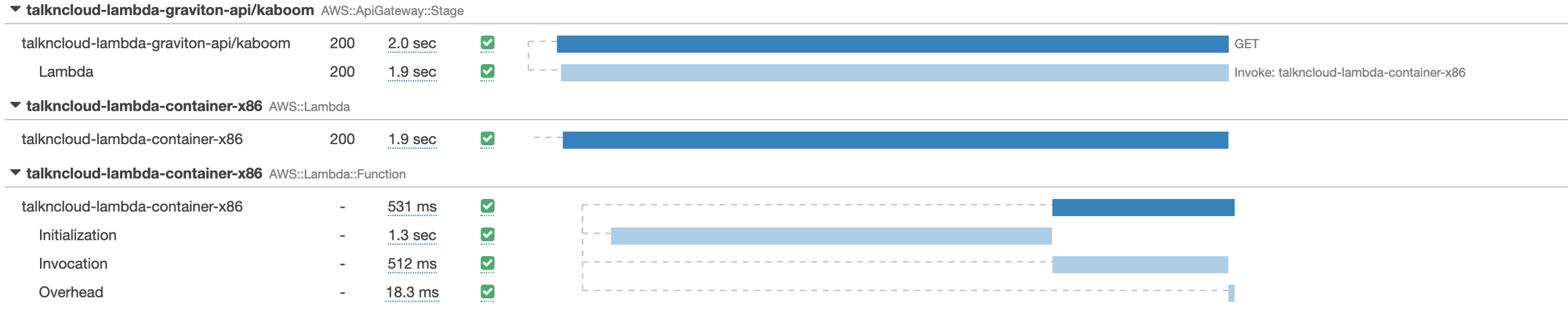
Longer cold starts aren’t the end the world, it was just something interesting I found along the way and unexpected. If we take a look at what the arm container is doing once its warmed up, it ticks along as per normal:
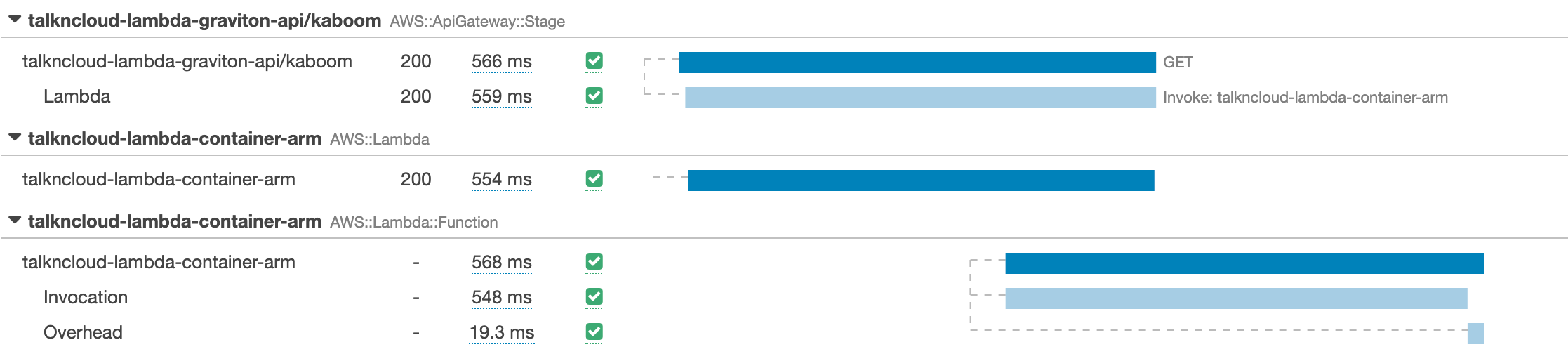
You can see the arm container trace, warmed up, not requiring initialization. Good stuff.
Duration stats table
Using CloudWatch insights I was able to query the function data to show the duration in milliseconds for each function, billed versus actual. Again, this shouldn’t be too surprising after seeing the cloudwatch charts above.
The surprising numbers being that x86 was quicker all round, not surprising after seeing the cloudwatch charts.
| Function | BilledDurationMS (Total) | DurationInMS (Total) |
|---|---|---|
| ArmContainer | 15216876 | 15180466.08 |
| x86Container | 13304215 | 13234641.51 |
| Arm | 14985048 | 14971569.68 |
| x86 | 12938295 | 12924734.27 |
Switching to Graviton2 with CDK
I wanted to talk briefly on how you go about implementing Graviton2 with CDK, the AWS blog has a better write up if you want to use the console but I’ll touch on CDK only.
Note: You’ll need to be on the latest version of CDK to do this.
When you develop a function in CDK there is a new property for functions which is architecture, if you don’t specify it defaults to x86, cool cool, no problems. But, if you want to choose an arch you are presented with an array, why would you need an array of architecture????
| |
It’s not entirely clear, the CDK team have already updated the documentation https://docs.aws.amazon.com/cdk/api/latest/docs/aws-lambda-readme.html#architecture which shows why this might be needed for layers but not really the core function. Once more, if you do this manually in the AWS console you are presented with a radio button, x86 or arm not both.
Note: this is as of CDK version 1.125.0
If you’re interested in reading the CDK github changelog, others are also asking this question. I suspect it will be fixed in a future release:
https://github.com/aws/aws-cdk/commit/b3ba35e9b8b157303a29350031885eff0c73b05b
Other than updating CDK and specifying the architecture thats all thats needed to deploy an arm/Graviton2 lambda function using CDK.
Containers and multi-arch
One thing that I didn’t really think of when I started going down the arm path was building containers without having an arm processor. I’m using cloud9 for some of my container work and it doesn’t run on Graviton2, when you provision using CDK it abstracts alot of the heavy lifting for you and it failed during the container build for arm due to the arch mismatch.
This just wasn’t something that I thought of initially, it’s very obvious now, but just something to think about if you need to use containers and Lambda, you’ll need to eat some engineering time to get it running.
Docker buidx seems to be the answer, so at the end of the day the tools behind the scenes are changing which should make it easier. It runs an emulator so that you can build the container for different supported architectures. I followed this AWS blog to setup my environment. Just scroll down to “Creating a multi-arch image builder” and you should be good to go.
Now, if you run provision the CDK stack with containers it will build successfully.
Wrapping up
One thing that I haven’t discussed is that Lambda with Graviton2 is cheaper, it’s actually priced differently.
us-east-1 128MB price per 1ms:
| Arch | Price (USD) |
|---|---|
| x86 | $0.0000000021 |
| arm | $0.0000000017 |
When I read the initial information coming from AWS and checked out the blogs, I was under the impression that it was cheaper because it was faster. Faster meant less milliseconds duration and less billing. But, no, as you can see from the AWS pricing its just cheaper in general.
I was expecting this to be more clear cut than it was, I wanted Graviton2 to be the clear winner hands down but it just wasn’t the case. When you factor in a little more dev time in multi-arch containers (if needed or keeping options open) and potentially having issues with library support there is a little more to consider than what you might think.
This is just a simple case of your mileage may vary, if you’re hitting the free tier and other features of Graviton2 don’t float your boat you’ll probably do nothing. If you’re paying serious dollars for Lambda right now then I’d be doing side by side comparison to make sure you get what you expect, every app is different.
I’m open to suggestions and feedback on the testing, this didn’t touch on an scaling or other scenarios so there is a bit more that could be done. Any other tests you can think of? If you’ve switched to Graviton2 with Lambda, how has it been?
Related Posts

AWS official Lambda layers with AWS CDK
This is my first official post since joining the AWS community builders and well it’s not super exciting but none the less it was a source of frustration for me so it might be for others…lambda layers.
Read more
Athena-express with AWS and federated query
For all the cool kids playing along you’d know that I posted a primer to AWS Athena a few days ago.
Read more
Hackster AWS Reinventing Healthy Spaces Challenge
We are only a couple of days away from finding out the results to the Hackster AWS Reinventing Healthy Spaces Challenge.
Read more