
AWS Athena primer
This post is about the basics of AWS Athena. Like many of the AWS products there is a bit to know about this beast and getting started can sometimes be a little challenging. I’ll lay this out so that you can get started using Athena and hopefully you’ll understand what it can do, this will be a brief intro.
A Greek goddess or a nice serverless SQL service?
Spoilers, AWS Athena is not actually a greek goddess but, if you’re using AWS you may find it more useful (or not, if you have access to the Greek Goddess, Athena, let me know, we’ll talk).
AWS Athena is in fact a serverless SQL service that enables querying of structured, semi-structured and unstructured data using that familiar SQL syntax that you’ve come to love/hate. Well, it’s a little more than that too…
Not feeling it? What if I told you that you could chuck a csv file on AWS S3 and query that file using SQL with Athena? This is something Athena can do, but it can also query relational databases which is handy if you’re already using other AWS services like RDS or even handier if you’re using DynamoDB because it can query that too!
What is a data source?
Athena supports many data sources, here are a few to get you interested:
- S3
- Query files directly from S3 in certain formats (CSV, JSON, ORC, Apache Parquet and Avro)
- CloudWatch (logs)
- MySQL
- Postgres
- DynamoDB (NoSQL)
- DocumentDB (MongoDB)
- Redshift (Data warehouse)
- Redis
- Apache HBase
Now, I know what you’re thinking. This is a great list, sure, but it’s not everything. I’m looking at you Oracle and MSSQL folk, haha. You can actually roll your own custom connector, there is an SDK so that you build out the connector to use in Athena to connect to data that isn’t supported above.
But, I suspect the AWS team will continue to grow the connectors if demand is there. Or more likely, you’ll just use S3 because it’s cheap and you have a bigger data strategy in mind.
Connectors, now we are talking…
If you’re already using AWS you know that S3 can be very cost effective and it might make sense to store a bunch of crap in a bucket that happens to be readable by Athena. But, what if you have a relational database already like PostGres or maybe NoSQL like DynamoDB?
This is where connectors come in, connectors are Lambda functions that integrate with Athena to provide the connectivity between Athena and your data source. AWS provide a boiler plate for many sources already and it should be enough to get you going.
The connectors provide the ability to perform Athena Federated Queries, which is basically anything that goes via Lambda. The Athena github repo has all of the connectors currently available.
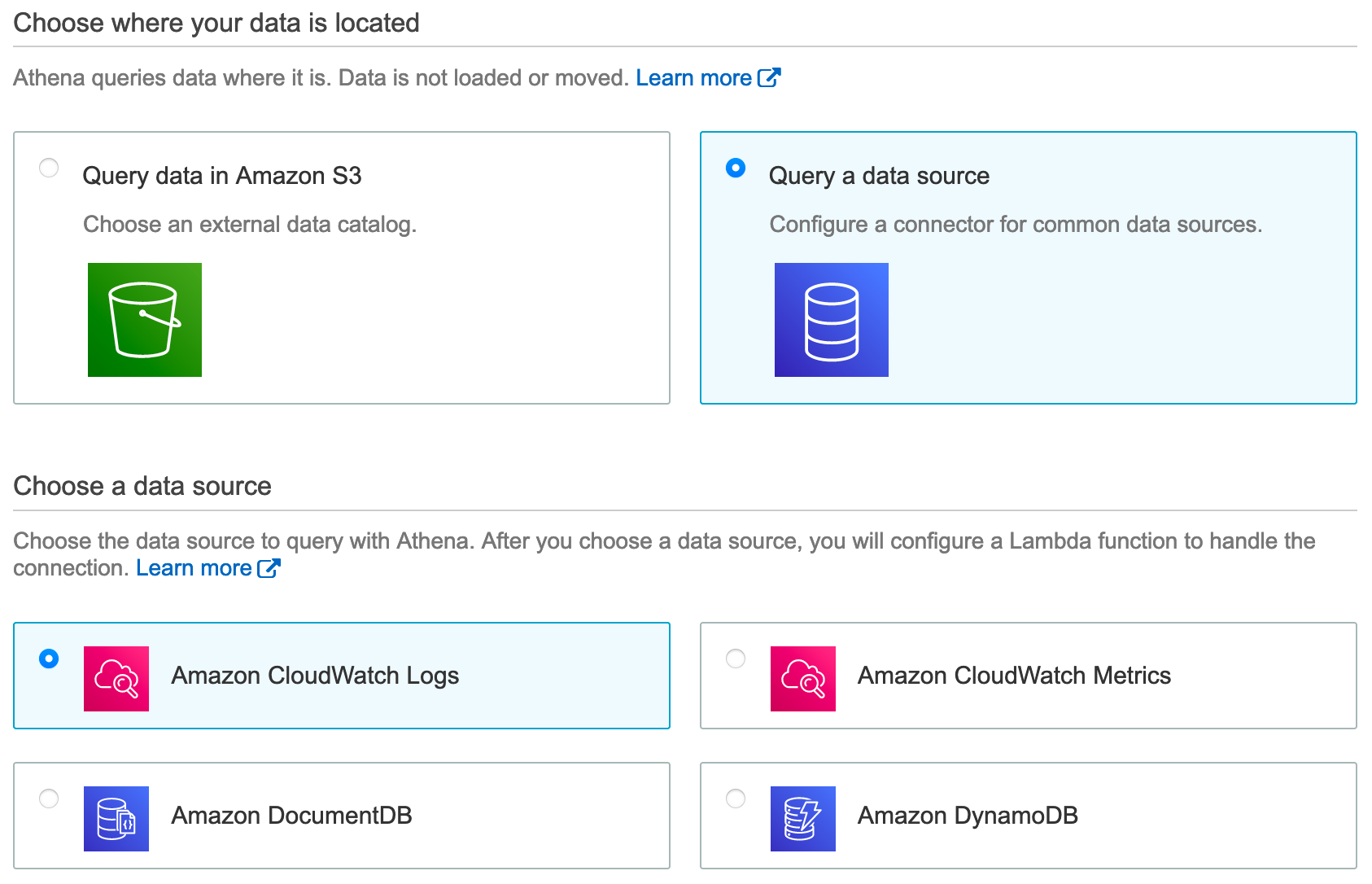
Note: You need to be running a version 2 workgroup, create a new one or upgrade your existing one. This is done in the Athena console.
Now, Athena Federated Queries has been around since late 2019, it’s come along way but you might find issues depending on your data source that you’ll need to work through. Some of that may involve setting up an AWS Glue schema, I don’t want to get into Glue but just know it’s out there it’s an ETL and it feeds into the AWS Athena patterns you’ll see kicking around.
Query basics
The management console for Athena gives you all the basics that you need to connect to a data source and start querying data. When you create a data source the results are actually stored in an S3 bucket (which you specify) and then those results are returned to you.
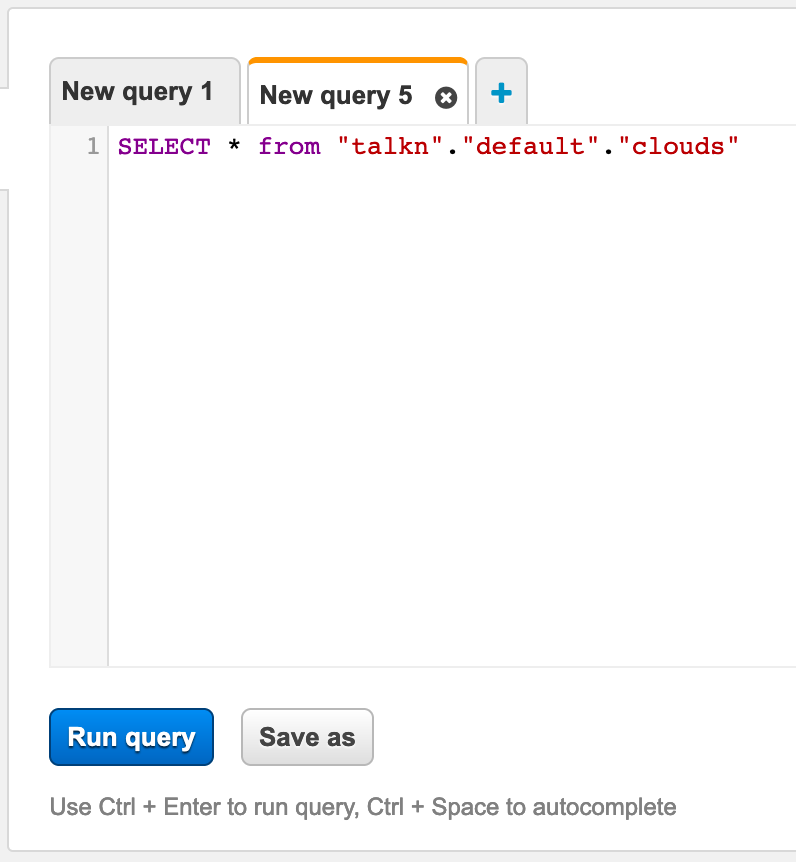
The console gives you a pretty good spread of features which allows you to save queries, view history etc. When you do execute a query you can also download that result set as a file. Which is handy.
As far as connectivity goes you can use Athena via the API, ODBC and JDBC there are various drivers out there for connecting using your client applications. You can also use the AWS SDK to query Athena using the something like Lamba or other custom applications.
TL;DR
Use Athena to query data in S3 and other data sources via connectors (Lambda) using Federated Queries. Athena can connect to sources in AWS and also on-premise (providing there is connectivity). This is a useful service for ad-hoc querying a bunch of different data sets and sources.
I’m keen to hear from others about how you are using Athena or if you’re not, why and what else are you using?
Related Posts

AWS temporary creds with SSO and a CDK workaround
It’s been a rainy past couple of days here so I’m catching up on some writing, something that i’ve been meaning to talk about for sometime is how to manage temporary credentials and access.
Read more
AWS Cognito, the good the bad the ugly and CDK
Alrighty, I’ve been using AWS Cognito for a while now and thought it was time for a write up. We’ll run through a quick overview and highlight the good and bad, there is also a CDK example provided in the talkncloud github repo.
Read more
AWS CloudFormation cfn-guard is now GA - hello policy as code
Last month AWS Cloudformation Guard (cfn-guard) became generally available (GA) and it’s a pretty cool addition by AWS which gets us started with policy as code.
Read more