It truly was a Shawshank Redemption…AWS Athena + DynamoDB + QuickSight for easy analysis (CDK)
You’re probably wondering why the title of this post mentions Shawshank Redemption and it’s a good question. I’m a big fan of Will Forte and if you’ve watched “The Last Man on Earth” tv series you’d know where the quote is from. But still, to answer the question, we will be using the movie data sample set to load into DynamoDB and in that sample Shawshank Redemption is still the number one movie!
Moving on…
I’m picking up where I left off on my previous AWS Athena posts, these posts discuss what AWS Athena is and federated queries. Go check them out if you’re unsure:
athena express with aws federation
I’ve managed to work out how to created animated gifs so this should make these posts a little more fun. We’ll be talking about the following design in AWS:

The problem
Alright, so here is the deal, you’ve been killing it. You’ve delivered this kick ass service using AWS and it’s costing a 6 pack of beer a month to run but you’ve got this seagull type manager or similar who keeps asking:
How many new items have been created? Can you grab me that record that looks like xyz?
It’s never enough is it!
Anyway, to be fair, it’s a pretty legitimate request. This is the downfall of DynamoDB unfortunately, it’s not straight forward to run basic queries over it that you can release to an end user. You could build your own dashboard or stats in your app and that’s fine for basic stuff but for proper analytics that becomes a can of worms pretty quick. Mainly because you find that users typically want BI like widgets etc and soon you’ve written Tableau.
A solution?
I’ve tackled this one by trying to simplify this to the point that the user still has a good experience and data analysts / product owners / seagulls have access to a powerful product (QuickSight) to build their own dash.
This was only possible this year, as I’ve mentioned in my previous posts, the AWS Athena team have been straight up owning it out there by delivering update after update. A special mention to the QuickSight team for enabling federated queries in Sydney, I reached out to support after I realised it was missing and they were able to enable it within days. Which was nice.
CDK
If you’ve read anything I’ve done you’d know I’m a big fan of Infrastructure as Code (IaC) fan and cloud development kit (CDK) is my jam. Surpise, that’s what I’ve used for this project. If you want to deploy this whole stack in your account just head over to my open source repo, clone the code and deploy. You should get something pretty close.
It won’t setup QuickSight, follow on to configure QuickSight.
 GitHub
GitHubAppSync
I’ve written a few posts on AppSync, all you really need to know is that AppSync is AWS’s managed GraphQL service. I’m using it here for one simple thing. A direct lambda query, which means rather than using all the goodness of GraphQL we are going to chuck a Lambda function into the mix.
The Lambda function attached to this query is basically doing the following:
- Check s3 bucket for data
- Is the data current?
- Fetch data using s3 select
- Fetch data using Athena-Express (federated query). Read about Athena-Express and the package changes.
- Update the cache if it had to fetch new data
Shout out to Trevor Harmon, I followed his write on S3 select which helped me out. Read the write up here.
Once you’ve setup AppSync and the function you can query it using the built-in query tool in AppSync, which is pretty neat.
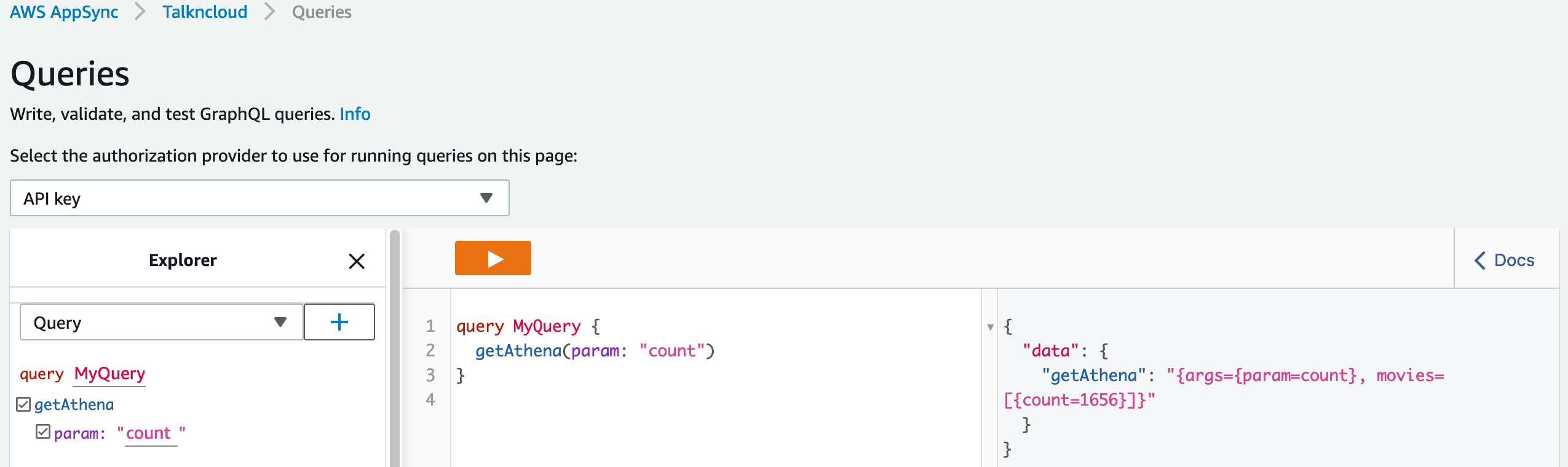
You may notice that I’ve made parameters in AppSync (schema), I wanted to throw that in for users just to show how you might want to split it out into multiple different queries etc. Returning all of the data in my second parameter probably isn’t the best idea, that is more of an example.
There are a bunch of different reasons why you might use Direct Lambda with AppSync. For this use case I’m using it because I want to know how many records are in the dataset, this is currently missing functionality from AppSync. You could maintain another dynamo table and query that instead, depends on what you are trying to do.
S3
I just want to touch on the s3 buckets for a second. The Athena result bucket is required, when Athena runs it outputs results to S3, that’s just how it works, you need it when you set it up.
The Cache bucket is a little different, I wanted to use S3 Select which allows you to query certain files like CSV directly from S3 this speeds up performance a whole bunch. So, all it’s really doing is grabbing the latest results from the federated query and updates the file in the cache bucket, this reduces the time for the user from 5 seconds to 1 second or less, unless you’re the first one and it’s a cache miss. Haha.
Athena Connector
AWS Athena Connectors are basically JDBC drivers in Lambda that integrate with Athena and your data source. When you deploy a new datasource you can select “query” type which will then ask to provision a connector. These connectors live in the AWS serverless app repo but you can also roll your own.
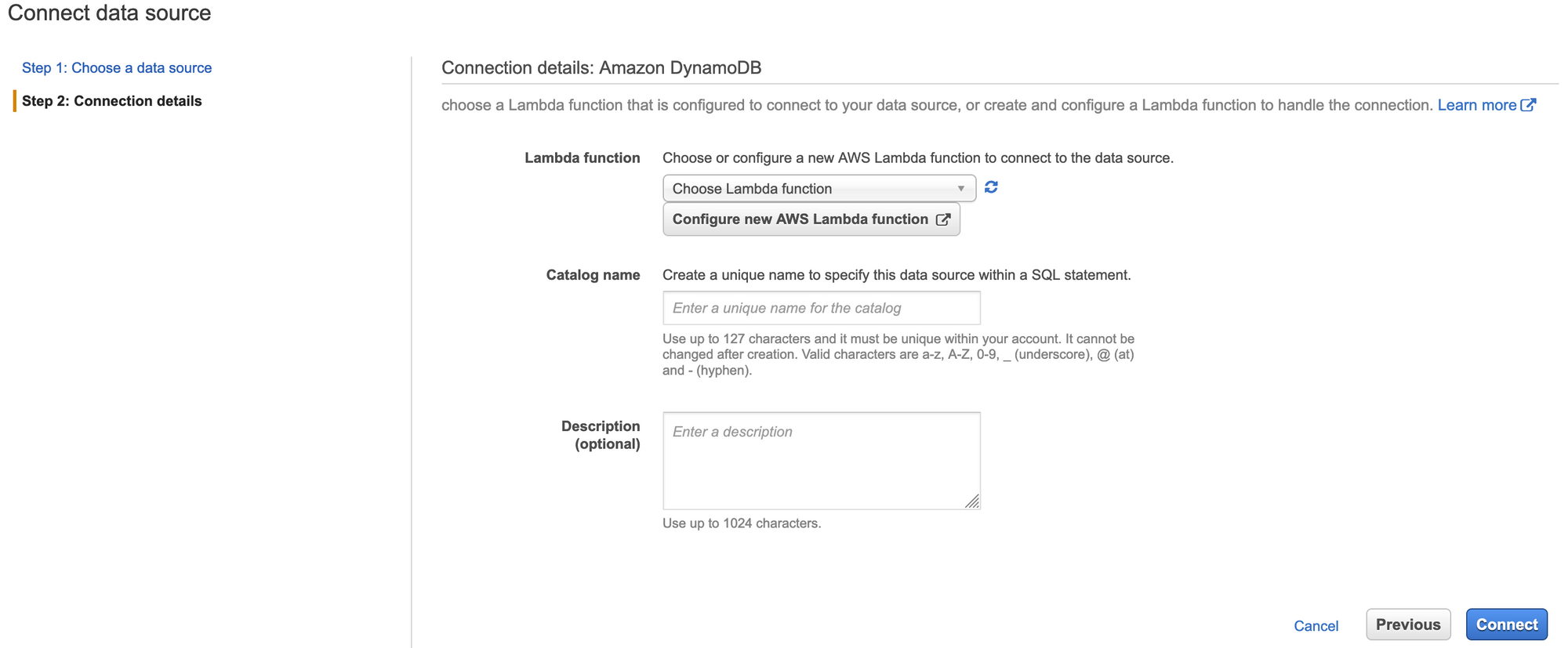
There are a few things to known about connectors:
- Connectors are associated to a work group, you need to be running version 2 work groups for federated queries (check your region for support)
- With DynamoDB it tries to do automatic inference on the data types, this doesn’t always work. You need to use Glue and mess around with types if this happens and then the connector will use Glue as well. We don’t need it for this.
- All of your db’s will be scanned. Yes. So with my second point if you want to query a single dynamo db and there is an issue with another db in the same account the connector will fail. You can’t target a single db (yet).
DynamoDB
Nothing special about DynamoDB. For this post I am using the movie data demo data which is discussed in another AWS post:
That post has a link to the demo data and shows you how to load it into DynamoDB.
I have also included a loader script in my repo for this post so you can use mine if that helps.
Update the “TableName” in the script before you run it otherwise it won’t load, also your endpoint if you’re not in Sydney.
QuickSight
The repo / CDK project does not contain any QuickSight configuration. This will have to be done manually. There is little support for QuickSight in CF & CDK.
If you don’t know anything about AWS QuickSight, it’s a BI tool, think Tableau, Power BI, somewhere where you can make dashboards (over simplification).
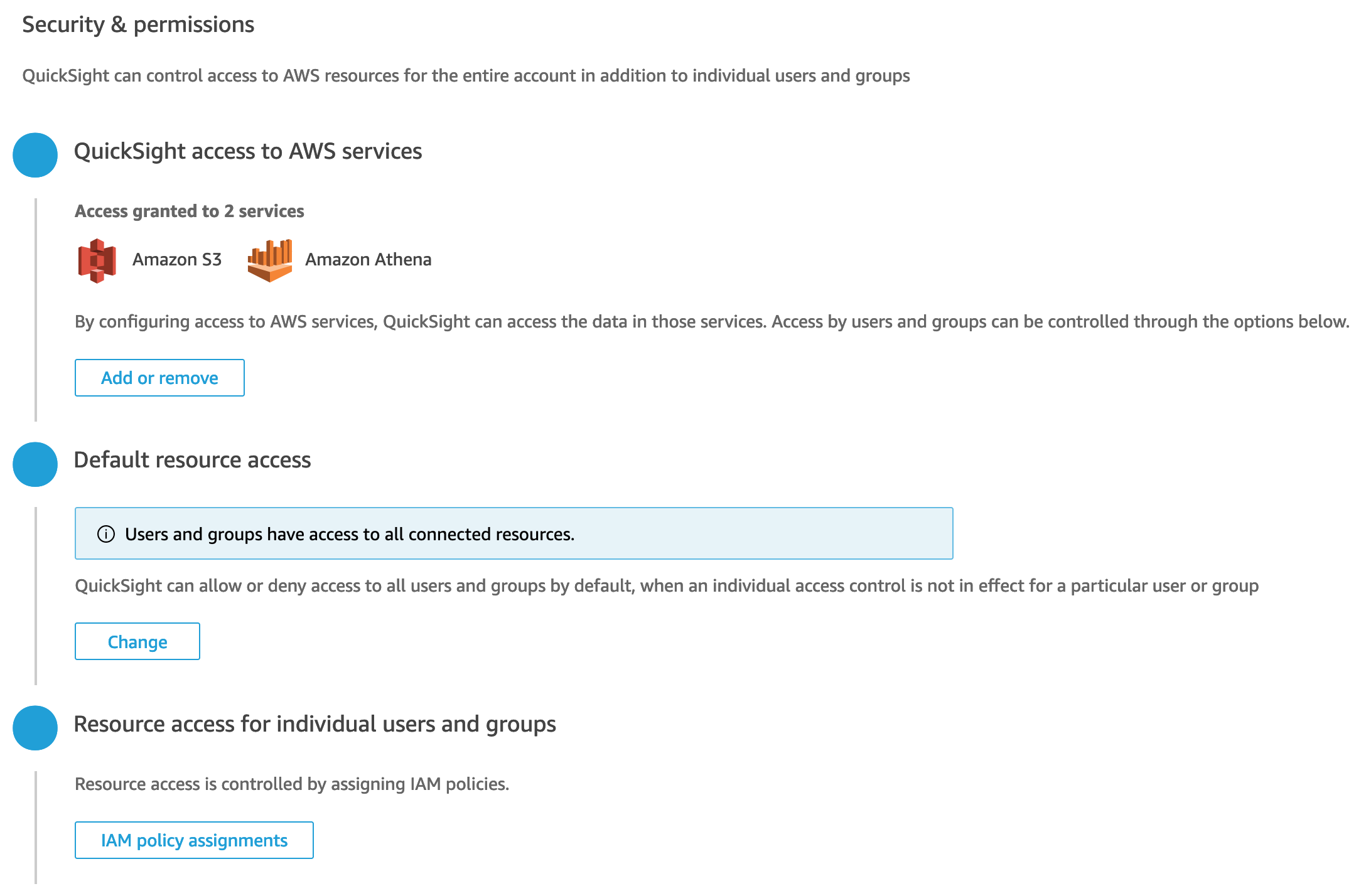
To setup AWS QuickSight you’ll need to head over to QuickSight in the console. Just select the cheapest plan if you don’t have one, you’ll get a trial period which means you can use QuickSight for free for a while.
- Add data sources
- Select Athena 3. Select Lamdba 4. Select the tnc function (connector)
- Select s3 6. Select the results buckets
Now when you add a data set you can select the connector which will query your dynamoDB data.
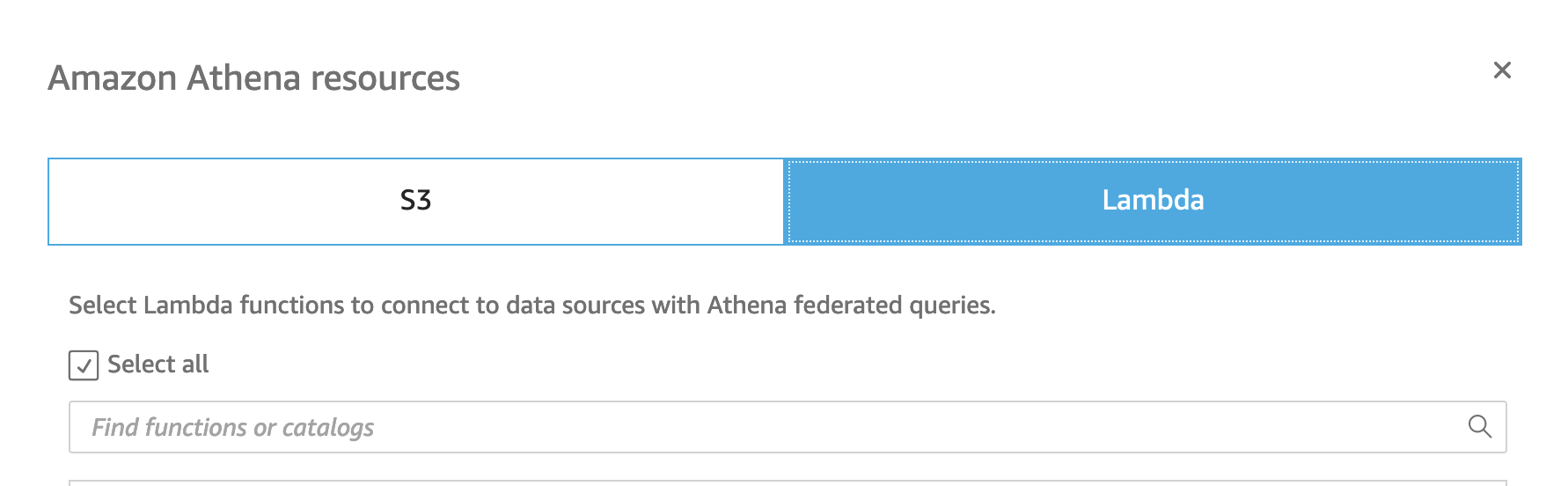
Add a data set
In the QuickSight console you can add a data set, select the tnc-wg or whatever yours might be called. Once confirmed you can select the data source and DynamoDB to query.
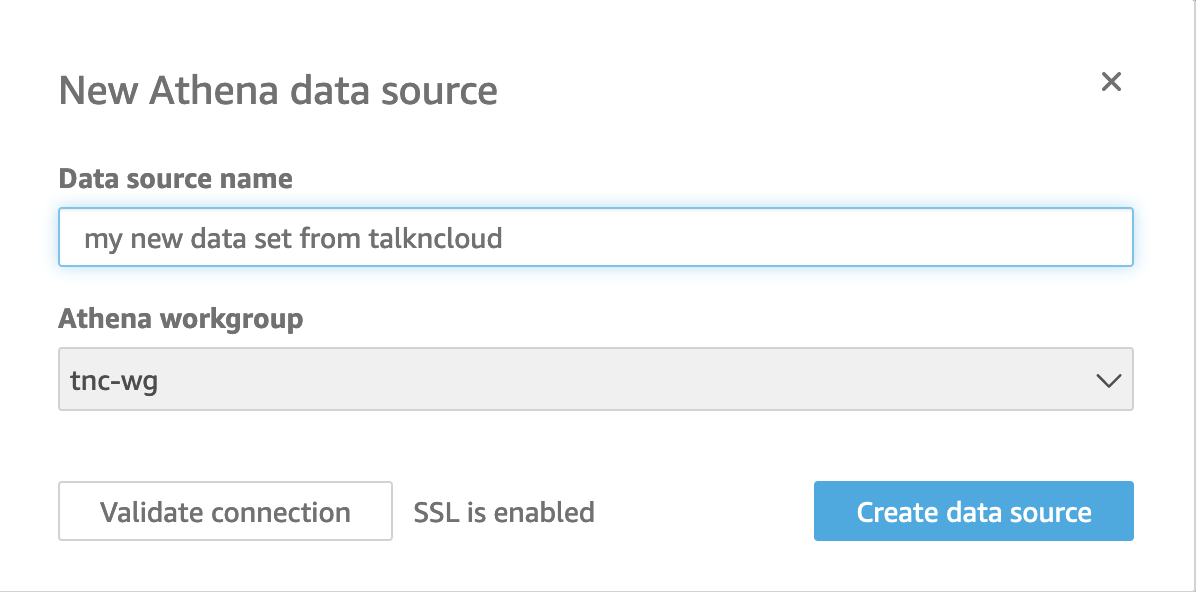
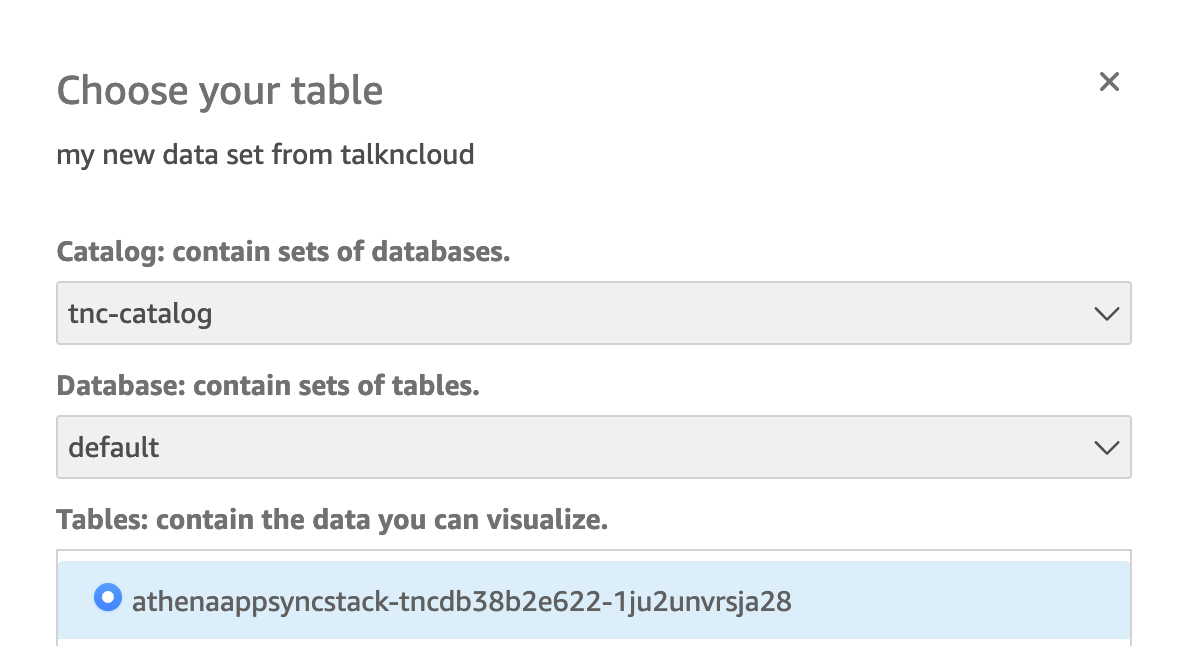
You’ll want to add it as a custom SQL query, use something like the following:
SELECT title, year, info.release_date, info.running_time_secs,
info.genres, info.image_url, info.rating, info.rank
FROM "tnc-catalog"."default"."AthenaAppsyncStack-tncdb38B2E622-1JU2UNVRSJA28"
Adapt the catalog and db as needed.
The reason I’m using a custom SQL query is because the data contains JSON, the parseJson function in QuickSight didn’t work (reach out if you know what I’m talkin about and can help out?) but this seems to work just fine.
I am also using SPICE, which is just an in memory function of QuickSight to speed it up, it does work and because we are using federated which can be slow, SPICE helps.
Add a new analysis
I won’t go into detail here but now you can create a new analysis and point it at your data set. You’ll get access to all the typical BI functions, widgets etc to create some really neat looking dashboards.
Some Results
Here are some samples that I built using this solution and analysing the results in QuickSight:
See, haha, Shawshank, still number 1!
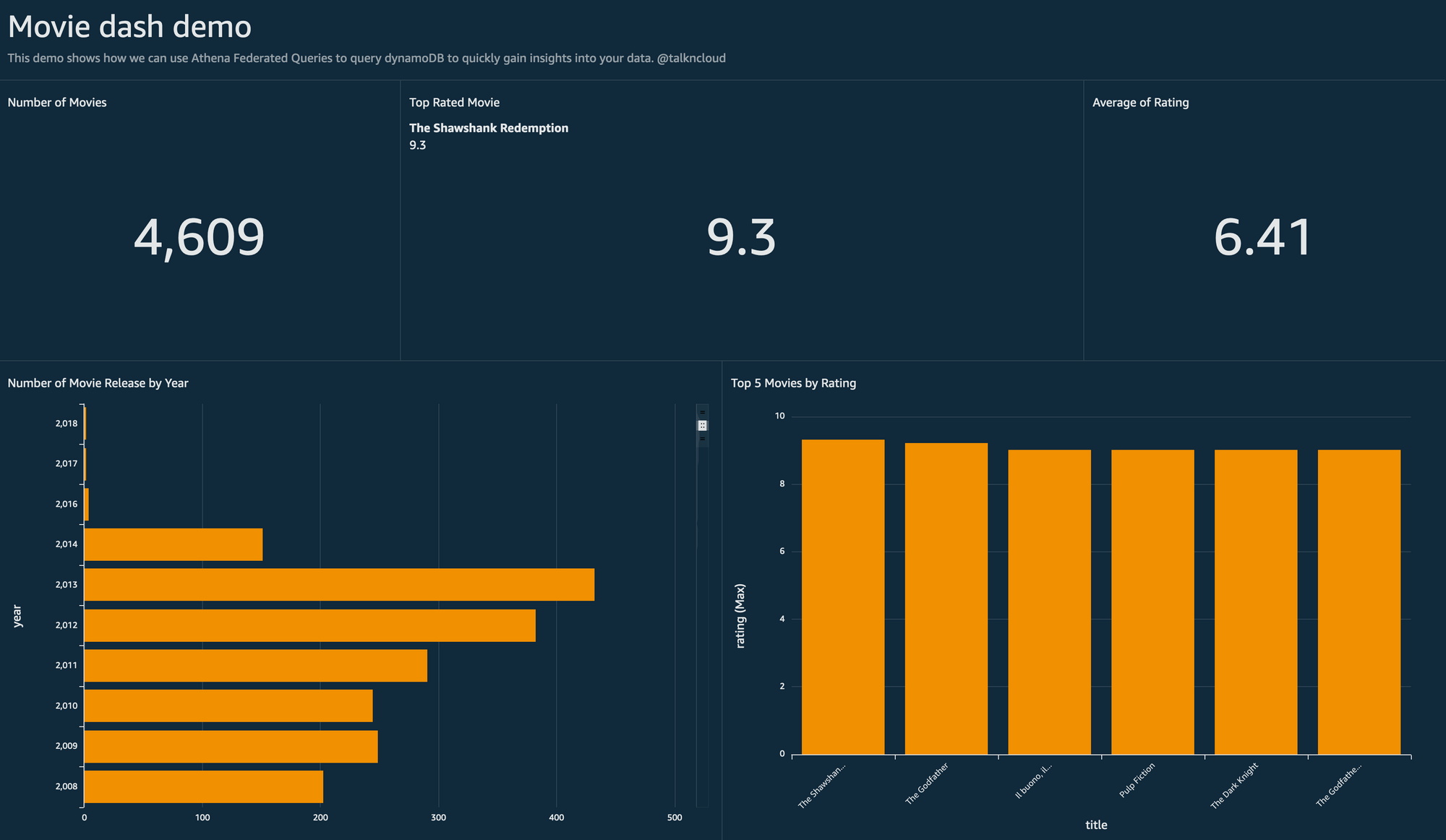
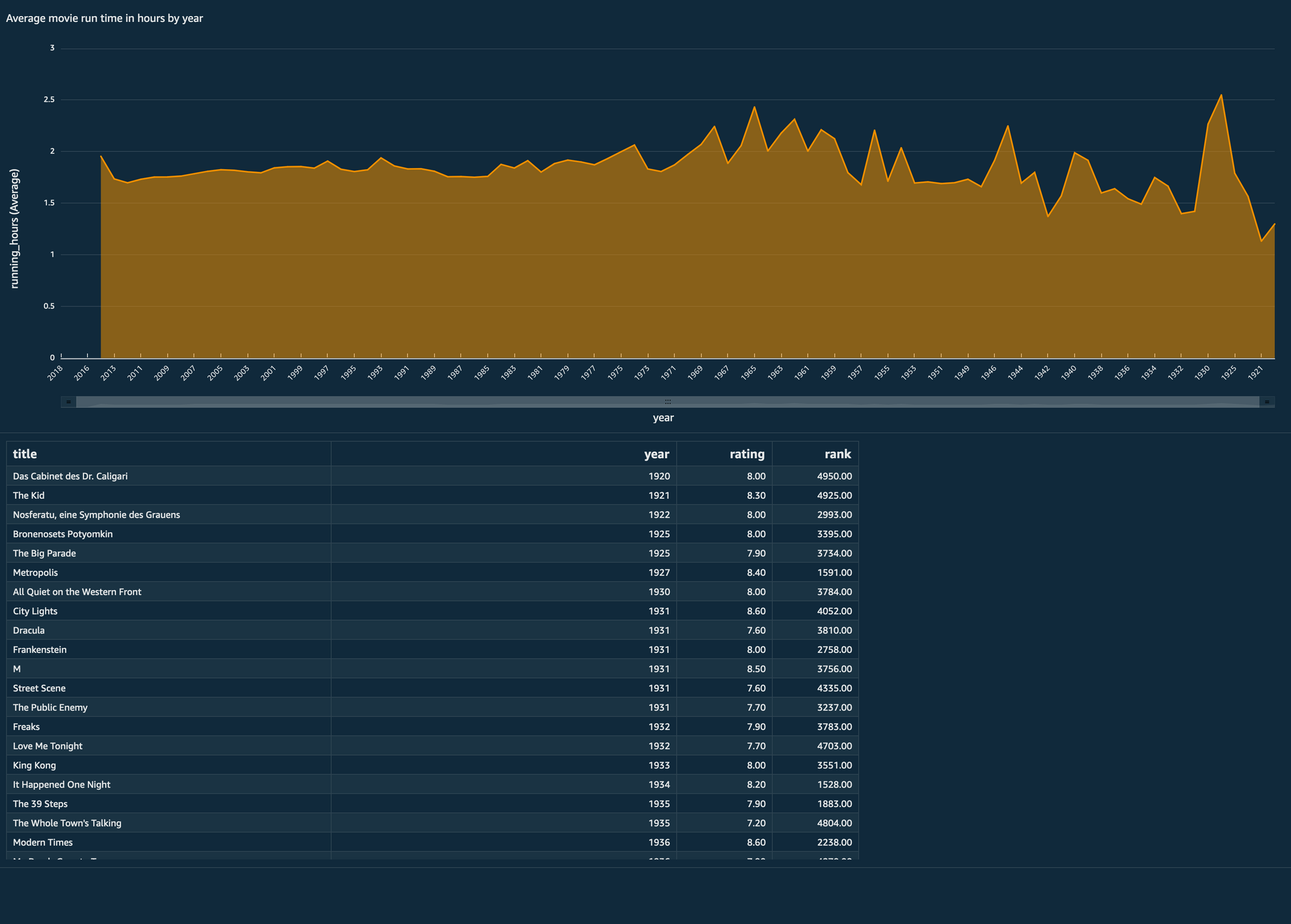

But what does it all mean?
This seems complicated, you’ve probably read something about streams in DynamoDB and Kensis and you’re wondering what i’m talkin about.
What we’ve setup is client side integration to Athena which is extremely powerful, you can run SQL queries across your data set and present them in your apps. Or you can just use Athena with your data scientist to run ad-hoc queries across your data.
We go beyond the AppSync client to reuse that configuration to hook it up to QuickSight so now you can really drill down into your data set using a point and click interface to run up some analysis very quickly. This analysis can be shared with others and is great for visuals.
That’s a wrap
It’s taken me a while to put all of this together, I needed to split this out into multiple posts as there is so much going on. For me peronally I really enjoyed using S3 select to see the performance difference and also the integration into QuickSight so now we can query our data in DynamoDB.
Keen to hear from others, I know querying DynamoDB is a bit of sore point in the AWS community. Let me know if this helps or you need more info and I’ll help out.
Related Posts

Athena-express with AWS and federated query
For all the cool kids playing along you’d know that I posted a primer to AWS Athena a few days ago.
Read more
AWS Athena primer
This post is about the basics of AWS Athena. Like many of the AWS products there is a bit to know about this beast and getting started can sometimes be a little challenging.
Read more
AWS temporary creds with SSO and a CDK workaround
It’s been a rainy past couple of days here so I’m catching up on some writing, something that i’ve been meaning to talk about for sometime is how to manage temporary credentials and access.
Read more